
The Quiet Backbone of the AI Economy
This massive growth reflects not only the rising role of AI in everyday life but also a shift from today’s largely text-based interactions to far more visually intelligent systems. As AI moves into multimodal perception, seeing, interpreting, and understanding the world, network capacity demands will climb even faster.
And this is only part of the story. A substantial share of tomorrow’s traffic won’t come from people at all, but from machines. As AI agents, autonomous robots, and intelligent systems operate at scale—gathering context, reasoning, collaborating with other systems, making decisions, and acting without human intervention, they will generate an immense surge in machine-to-machine communication.
Distributing intelligence
The impact of AI extends beyond mere traffic volume; it also necessitates a fundamental architectural transformation.
Today, the majority of AI processing is concentrated in the training of large language models (LLMs) housed within massive, centralized “AI factories.” These hyperscale facilities consume extraordinary amounts of compute and storage to create ever more capable models.
However, this dynamic is set to shift dramatically. McKinsey & Company estimates that by 2030, 60 to 70 percent of all AI workloads will be dedicated to real-time AI inferencing. As AI adoption accelerates, the center of gravity will move from training models to serving predictions and answering questions, responding instantly to humans, machines, and other AI agents.
This shift will push AI workloads outward, closer to where the requests originate. In many ways, it echoes the transformation brought by CDNs in the video era. Just as video delivery moved to the
edge to improve performance and scale, AI inference will increasingly be distributed across networks to meet the latency, cost, and capacity demands of real-time intelligence.
The network cloud continuum
Several powerful forces are driving the need to distribute AI workloads.
For business-critical and mission-critical applications, real-time processing is non-negotiable. Achieving this requires high-speed connectivity and ultra-low latency. Bringing inference closer to the user or device not only improves responsiveness but also reduces the volume of traffic traversing the WAN, cutting bandwidth consumption and improving overall efficiency.
Security and privacy concerns add another compelling reason. Localization of sensitive data and minimizing its movement across networks reduces exposure and aligns with increasingly stringent regulatory requirements.
Operational considerations matter as well. Distributing AI workloads allows operators to place compute resources where power and cooling resources are available and cost structures are most favorable. And in environments with limited or expensive connectivity, localized inference delivers far better performance and reliability.
All of this is pushing the industry toward a network cloud continuum, a world where AI processing happens everywhere. Some inference will run directly on devices such as smartphones, laptops, and wearables, albeit limited to tiny or very small models due to constraints in compute, memory, and power. A much larger share will be executed across a spectrum of cloud environments: on-premises enterprise clouds, metro and edge clouds, and centralized hyperscale regions, each interconnected by high-performance networks (Figure 3).
This continuum is already emerging, and it will become the defining architecture of the AI era.
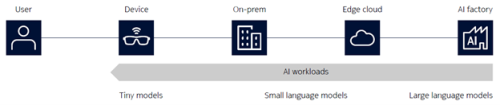
Figure 3. The network-cloud continuum
click to
enlarge
The shift from centralized data centers to a highly distributed architecture has profound implications for network design. It’s no longer just about adding capacity to support new use cases and AI-driven applications. The architecture of the network itself must be reimagined.
AI introduces requirements that stretch from the heart of the data center to the most remote points of end-user access. Delivering real-time intelligence at scale demands an end-to-end infrastructure built for low latency, massive bandwidth, and seamless coordination across every layer of the network.



