

LLMs on Commodity Hardware: What,
Where, Why AI PCs Are Already Here
The results show, as expected, that the Nvidia GPU platform yields the best performance. If the A100 were combined with a lower-power desktop chip, the efficiency, tokens/second/Watt, would be better, but it would still significantly lag the Apple M-series platforms. Specifically, we expect a desktop CPU would dissipate on the order of 100W instead of the data-center configuration’s 300W. The Nvidia A100 (or the rough consumer equivalent, the GeForce 4090) would dissipate the same power regardless.
The general trend of results shows that smaller but still capable models, e.g., the llama-2-7B-chat with seven billion parameters, run with very good performance on most consumer hardware even without the help of a GPU. Despite being smaller than the LLaMA-2-70B-chat model, Mixtral-8x7B-instruct exceeds it on objective evaluations of accuracy (response quality, not shown). Mixtral has faster inference than LLaMA-2-70B because it uses the modern MoE architecture, which engages only one-fourth of the model’s parameters at any one time. The Xeon is a good stand-in for modern consumer x86 CPUs since the core micro-architectures are similar.
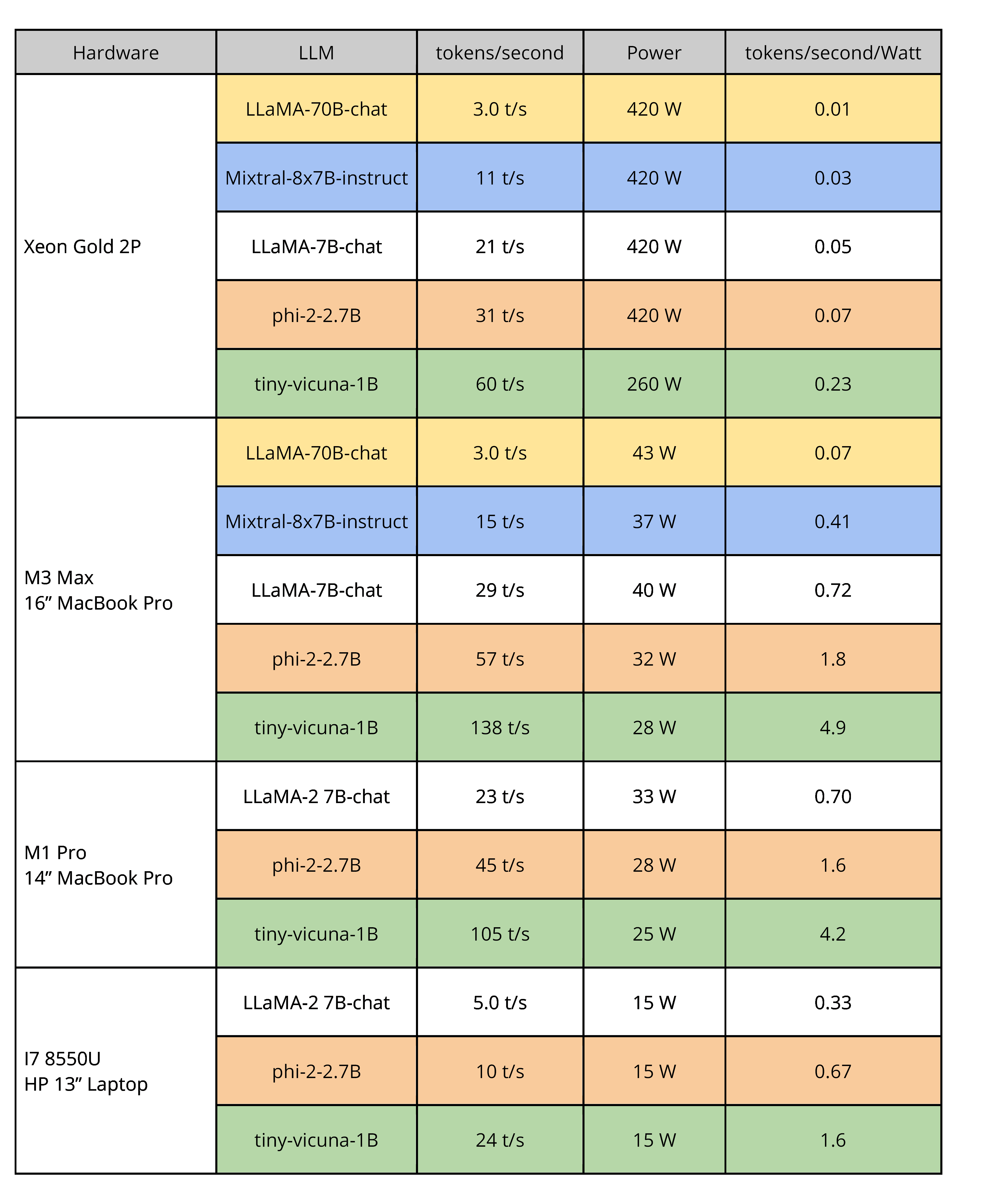
Table 4. CPU-only inference speed and performance-per-Watt for all model sizes that can run on each platform (limitation due to memory capacity on the low-end
laptops). Note the high-end laptop outperforms the server on all but the largest model.
The phi-2-2.7B model is an example of a smaller model that nonetheless produces high-quality results. Microsoft created this model with the explicit goal of training on higher-quality data to see if that could endow a smaller model with higher-quality output, and results show that it does. Phi-2-2.7B produces accuracy on par or



