

LLMs on Commodity Hardware: What,
Where, Why AI PCs Are Already Here
The A100 is still very useful for inference, but as of Nvidia’s latest announcements, it is now two generations behind their leading-edge AI hardware. In addition, we ran llama.cpp on Apple MacBook Pro laptops with the M-series chips. These chips integrate a multi-core CPU with a capable GPU in the same SoC (system-on-chip). The same microarchitecture is implemented in Apple’s iPhone handsets — though with fewer cores — so we can postulate that today’s low-end MacBook performance is tomorrow’s iPhone performance. We expect other smartphone platforms to keep pace due to competitive pressures.
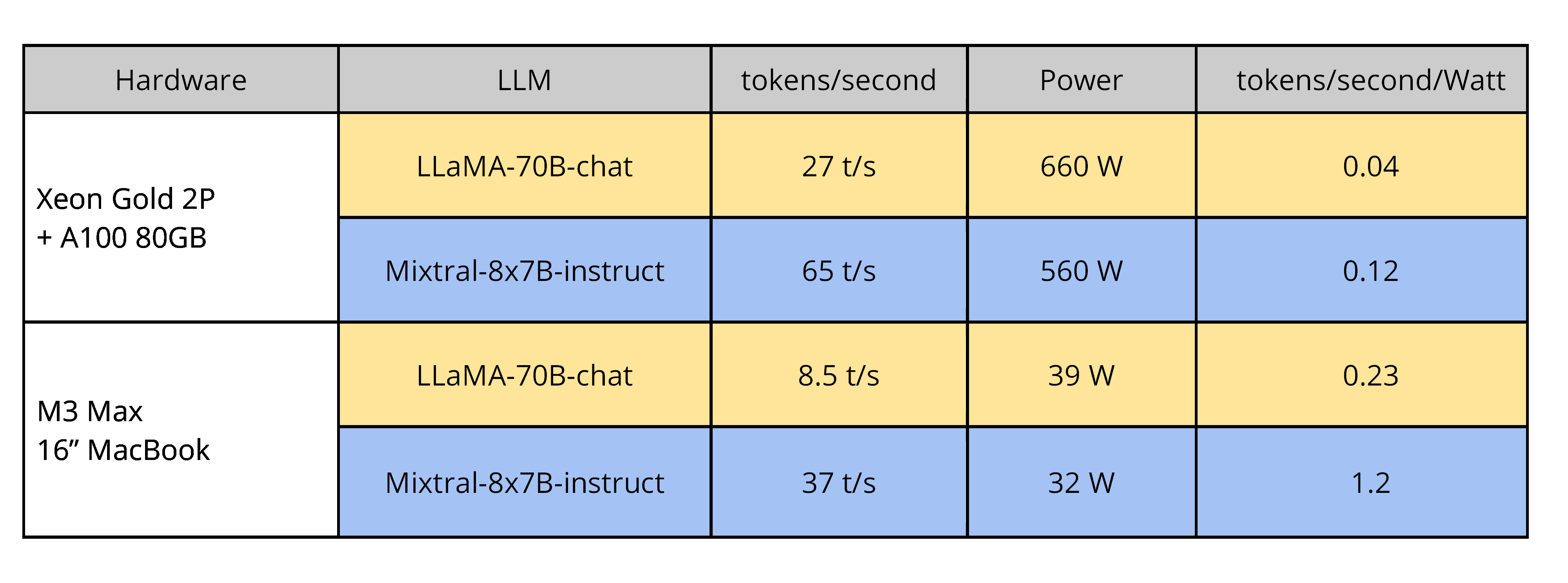
Table 2. CPU plus GPU inference speed and performance-per-Watt for large models on server and high-end laptop. The MoE Mixtral-8x7B has both better accuracy (response quality; not shown) and better speed than the large LLaMA model.
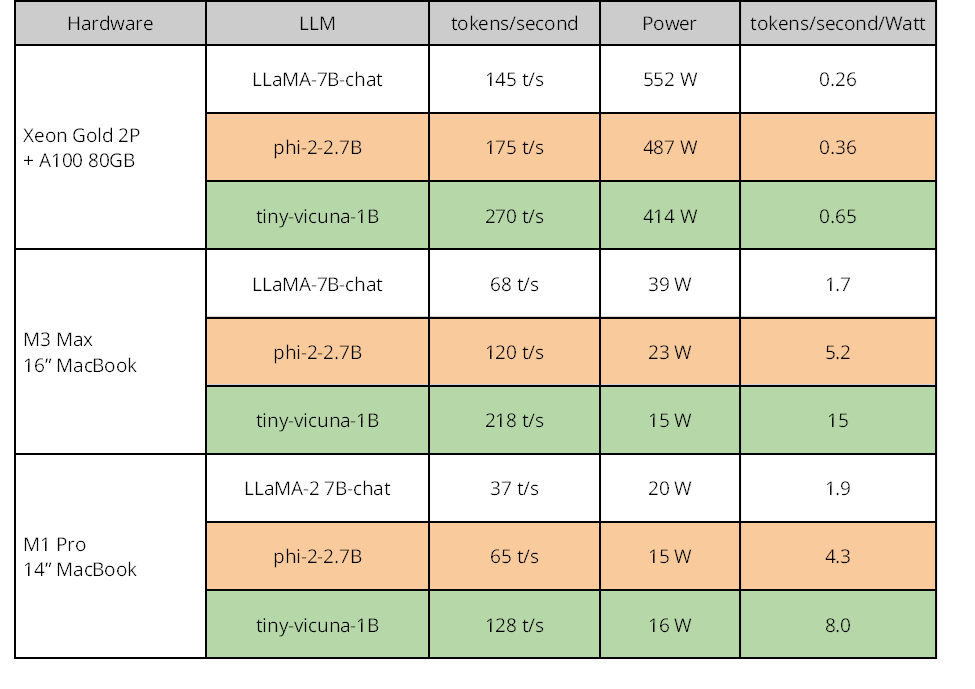
Table 3. CPU plus GPU inference speed and performance-per-Watt for smaller models.
To put a bound on the low end, we employ one past-generation Intel x86 microprocessor in an HP laptop; as with the sever platform, it’s running Linux.
We will compare a small selection of models and sizes to get a sense for what is possible currently: two LLaMA-2 models — 7B-chat (small at seven-billion weights) and 70B-chat (largest at seventy-billion); the state-of-the-art Mixtral-8x7B-instruct mixture-of-experts (MoE) model (large at fifty-six billion total parameters with fourteen-billion used at any one time); and the two small models — phi-2-2.7B (small at 2.7-billion) and tiny-vicuna-1B (smallest at one-billion). All models will be run with 4-bit quantization in the format known as GGUF, which is the native quantized format for llama.cpp. We show results for five models on the memory-rich platforms and three models on the memory-constrained. For high-end GPU-assisted results, we compare the largest models separately.
Consult Tables 2 and 3 (above), and 4 (on next page) to see the results. Each row is for a single model on a single platform, and there are columns for raw speed



