

Network Intelligent Agent Automation
Well structured automated operations systems will not be islands.
Granularity is typically determined by a combination of the requirements and the subsystems already in place in the overall system. Some are tempted to use the same granularity in the
automated system as in previous generations of manual operations systems. This is not a good idea. Manual and intelligent agent systems have different capabilities and different strengths /
weaknesses. Thus, it is better to start with a clean sheet analysis of granularity.
Such a clean sheet analysis may lead to a single automated system handling communications, computing and storage - operations and security. However, it may be prudent to start with automated
operations in one area in one domain. An area that is particularly troubling. For example, protecting against particularly concerning cybersecurity attacks. Then expanding, step by step to the
rest.
Well structured automated operations systems will not be islands. They will work well with manual staff who supervise and manage them. They will also interface with other functional units such as finance, marketing, planning, and so on. Some of those other functional units may be automated, manual or a combination of the two. The automated operations system needs to be able to work well with a high degree of volatility in these other functions as they each move to implement intelligent agents and business changes occur.
Well structured automated operations systems will not be islands. They will work well with manual staff who supervise and manage them. They will also interface with other functional units such as finance, marketing, planning, and so on. Some of those other functional units may be automated, manual or a combination of the two. The automated operations system needs to be able to work well with a high degree of volatility in these other functions as they each move to implement intelligent agents and business changes occur.
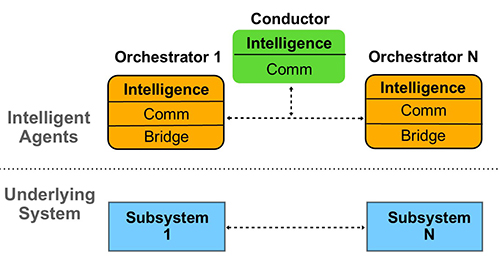
Illustration 1: Generic Intelligent Agent Architecture
Development
Development starts with a series of key decisions. The first is choosing what tools to use. There are a range of development approaches from all code to all LLM. There are a range of choices in
what LLMs do from all code to no code. At the all code extreme, they can be used entirely to create deterministic code modules that are combined to make the Orchestrators. At the no code extreme,
they can be used to perform all the functions in the Orchestrator. If an all code approach is chosen, a single LLM such as Claude Code housed in a data center is used. If a no code solution
is chosen, each Orchestrator is composed of one or a number of LLMs. These can be relatively small LLMs that are run either in a data center or locally. Tools such as N8N, OpenClaw, and NemoClaw,
etc. can increase development productivity. There is a wide and rapidly changing set of tools that can increase development productivity. Therefore, it is important to spend effort
to keep current on tools.
At this stage of the evolution of GenAI and its supporting infrastructure technologies, it is common for a combination of no code and code to be used. The tradeoff between the two is a
function of efficiency. For example, a Bridge may be created with code. Such a code module may be relatively small and consume very small amounts of system resources. While an LLM
implementation of a Bridge may consume larger amounts of resource. On the other hand, the interpretation of behavioral data from an underlying system in an Orchestrator may be done more
effectively and efficiently by an LLM.
The location of Orchestrators and Conductors can range from being fully centralized to fully distributed. The choice is a function of the geography of the underlying system, the requirements,
CAPEX/OPEX, organization structure and legal/regulatory conformance considerations.
Once these development approach decisions have been made, building can begin (agent developers are now being called “Builders”). The building process is one of taking the requirements (see Illustration #2 on page 3) and the architecture (see Illustration #1 above). Making decisions about what LLMs to use. Loading their context widows. Turning the requirements into inference prompts used by the LLMs. Composing the results into Orchestrators and Conductors.
Once these development approach decisions have been made, building can begin (agent developers are now being called “Builders”). The building process is one of taking the requirements (see Illustration #2 on page 3) and the architecture (see Illustration #1 above). Making decisions about what LLMs to use. Loading their context widows. Turning the requirements into inference prompts used by the LLMs. Composing the results into Orchestrators and Conductors.



