

The Race to Build AI-optimized Data Center Networks
![]() Network latency is among the most critical considerations for back-end AI infrastructures, as even a single delayed flow can block the
progression of all nodes. This is already a problem with today’s comparatively smaller-scale AI workloads, where Meta reported that roughly one third of AI elapsed time was spent waiting on the network. These issues can create frustrating delays in AI model training. In emerging real-time AI
inferencing scenario — such as responding to a live customer query, applying computer vision to identify flaws in a production line, or controlling industrial robotics — they can render the
application unusable.
Network latency is among the most critical considerations for back-end AI infrastructures, as even a single delayed flow can block the
progression of all nodes. This is already a problem with today’s comparatively smaller-scale AI workloads, where Meta reported that roughly one third of AI elapsed time was spent waiting on the network. These issues can create frustrating delays in AI model training. In emerging real-time AI
inferencing scenario — such as responding to a live customer query, applying computer vision to identify flaws in a production line, or controlling industrial robotics — they can render the
application unusable.
AI application workloads running in the data center are also highly sensitive to packet loss. Missing or out-of-order packets can dramatically increase latency due to network buffering and retransmission. Many AI operations, such as model training, can’t even complete until all packets are received, and packet latencies of even 0.1 percent can cause extreme delays that disrupt mission-critical AI applications. Given these factors, back-end AI fabrics must also be lossless.
Finally, model training and other complex, distributed AI applications require the ability to scale efficiently to trillions of parameters and beyond. Traditional fabric architectures using Compute Express Link (CXL), Nvidia’s NVLink, or PCI Express (PCIe) can meet the connectivity needs of smaller AI workloads. As operators look to support larger AI applications, however, they will need to consider scale-out AI leaf and spine architectures. Moderate “rack-scale” applications will require thousands of xPUs connected via an AI leaf layer. Large AI applications employing tens of thousands of accelerators will need data center-scale architectures with a routable fabric and AI spine.
Surveying Interface Trends
There’s an easy way to gauge the speed at which AI applications are coming to dominate modern data centers: follow the interfaces. As AI models grow more complex, they require more bandwidth per accelerator. We can watch the market responding to this pressure in real time, as data center operators increasingly adopt next-generation interface speeds, moving from 400 to 800 Gbps, and soon, 1.6 Tbps. (Figure 2)
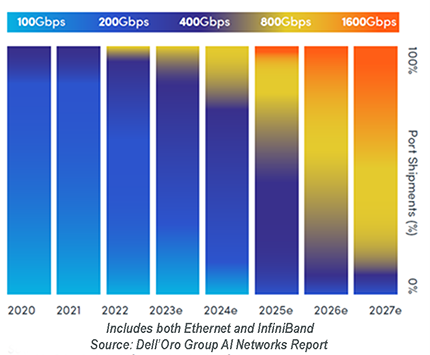
Figure 2. Accelerating adoption of high-speed interfaces.
The specific interface technologies that AI clusters will use remains an open question. Many operators prefer Ethernet when possible, as it’s a widely adopted, standardized, and cost-effective option. However, Ethernet is lossy by design, using priority-based queuing and pausing to handle congested links. Operators will therefore need to deploy it in conjunction with protocols like RDMA over Converged Ethernet, version 2 (RoCEv2) — or in the future, Ultra Ethernet Transport (UET) — to deliver the performance needed for applications like AI training. Alternately, proprietary InfiniBand can provide a lossless medium with more deterministic flow control. Where will the



