

Semantic Folding: A Brain Model of Language
Document-SDR – Sparse Distributed Document Representation
The word-SDRs represent atomic units and can be aggregated to create document-SDRs (Document Fingerprints). Every constituent word is converted into its Semantic Fingerprint. All these fingerprints are then stacked and the most-often represented features produce the highest bit stack.
The bit stacks of the aggregated fingerprint are now cut at a threshold that keeps the sparsity of the resulting document fingerprint at a defined level (see Fig. 2 on previous page) .
The representational uniformity of word-SDRs and document-SDRs makes semantic computation easy and intuitive for documents of all sizes.Applying similarity as the fundamental operator
Due to the topological arrangement of the Semantic Fingerprints, similar words or texts do actually have similar Semantic Fingerprints. The similarity is measured in the degree of overlap between the two representations (see Fig 3).
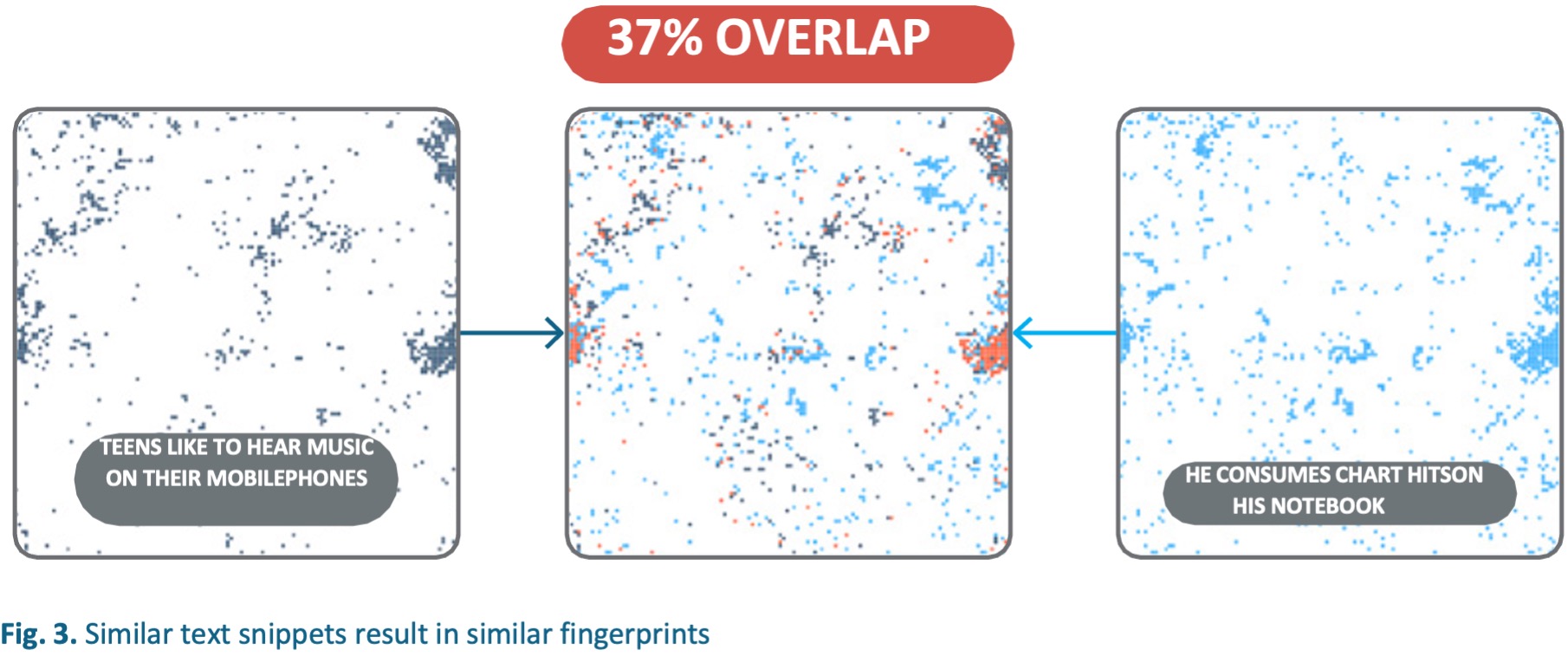
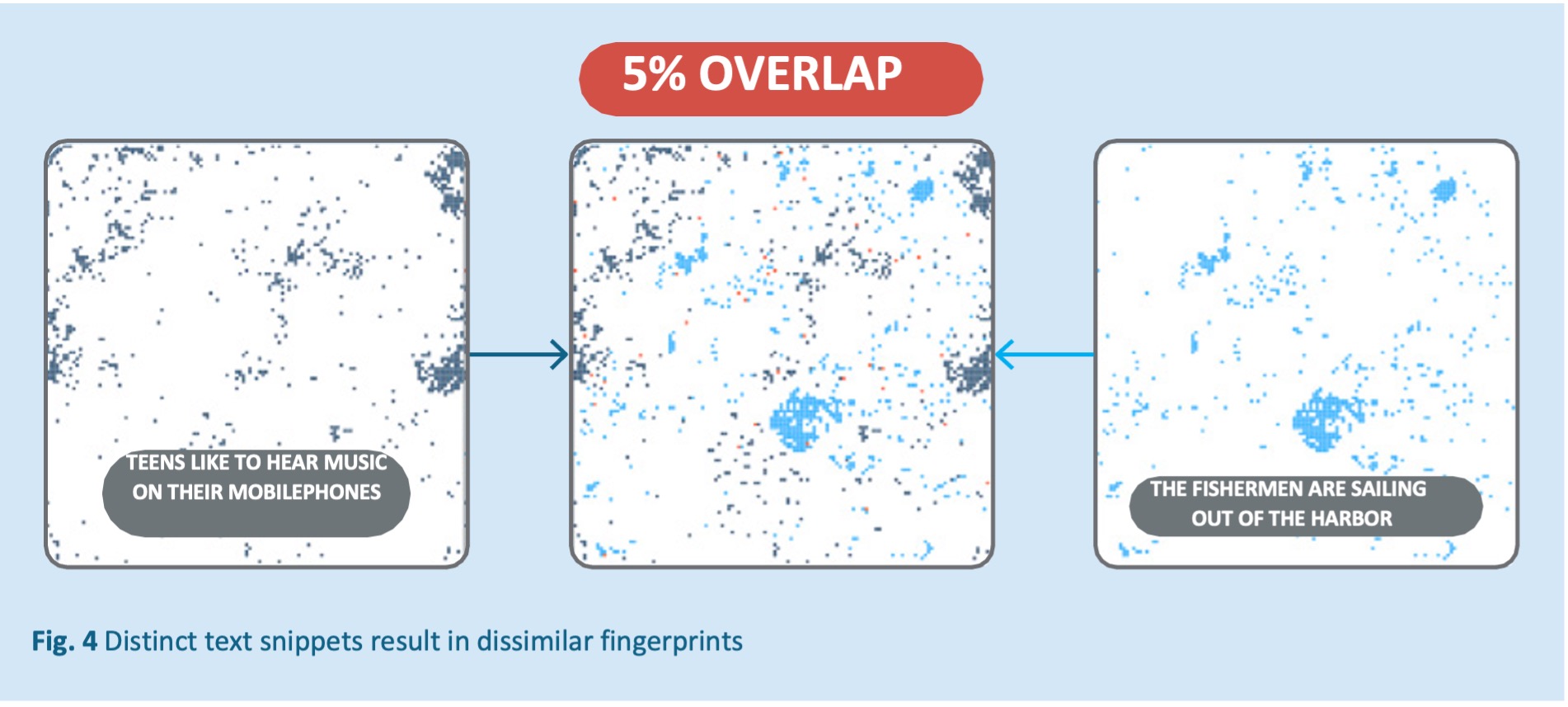
There are two different semantic aspects that can be detected while comparing two Semantic Fingerprints (see Fig 4):
- The absolute number of bits that overlap between two fingerprints describes the semantic closeness of the expressed concepts.
- By looking at the topological position where the overlap happens, the shared contexts can be explicitly determined.
Because they are expressed through the combination of 16K features, the semantic differences captured by a Semantic Fingerprint can be very subtle.
Semantic Folding opens new horizons for automating workflows involving large volumes of complex documents that currently still rely on human review and interpretation, like contract analysis and
insurance policy review. With its ability to understand the meaning of natural language and to process data in real time, Semantic Folding offers also a great opportunity to build next generation
Know Your Customer tools by extracting insights from media posts and online customer reviews.



