

Semantic Folding: A Brain Model of Language
Definition of a reference text corpus of documents that represents the Semantic Universe the system is supposed to work in. The system will know all vocabulary and its practical use as it occurs in this Language Definition Corpus (LDC). By selecting Wikipedia documents to represent the LDC, the resulting Semantic Space will cover general English. If, on the contrary, a collection of documents from the PubMed archive is chosen, the resulting Semantic Space will cover medical English.
Every document from the LDC is cut into text snippets with each snippet representing a single context. The size of the generated text snippets determines the associativity bias of the resulting Semantic Space. If the snippets are kept very small (1-3 sentences), the word Socrates is linked to synonymous concepts like Plato, Archimedes or Diogenes. The bigger the text snippets are, the more the word Socrates is linked to associated concepts like philosophy, truth or discourse. In practice, the bias is set to a level that best matches the problem domain.The reference collection snippets are distributed over a 2D matrix (for example 128x128 bits) in a way that snippets with similar topics (that share many common words) are placed closer to each other on the map, and snippets with different topics (few common words) are placed more distantly to each other on the map. This produces a 2D semantic map.
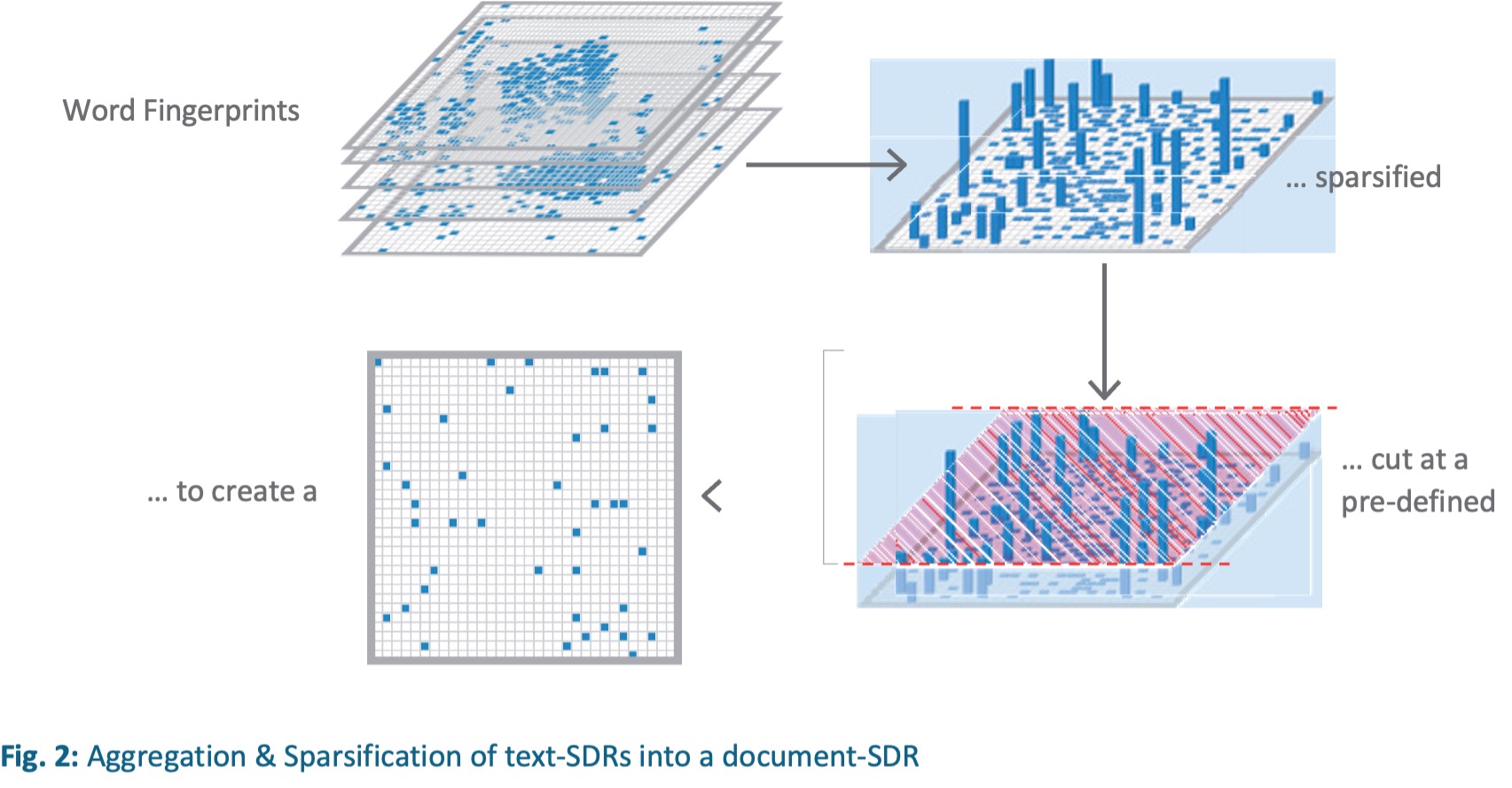
Word-SDR – Sparse Distributed Word Representation
With Semantic Folding, it is possible to convert any given word (stored in the Semantic Space) into a word-SDR, also called a Semantic Fingerprint. The Semantic Fingerprint is a vector of 16,384 bits (128x128) where every bit stands for a concrete context (topic) that can be realized as a bag of words of the training snippets at this position.
Let's consider the Semantic Fingerprint of the word jaguar (see Fig. 1 on previous page). It contains all the different meanings associated with this term, like the animal,



